최장 증가 부분 수열이란?
어떤 임의의 수열이 주어졌을 때, 수열에서 앞에서부터 차례대로 몇 개의 숫자들을 뽑아서 부분수열을 만들 수 있다. 이렇게 만들 수 있는 부분수열 중 오름차순으로 정렬된 가장 긴 수열을 최장 증가 부분 수열(LIS, Longest Increasing Subsequence)라고 한다.
예를 들어 [5, 2, 1, 4, 3, 5] 라는 수열이 있다고 가정해보자. 해당 수열에서 최장 증가 부분 수열에 해당하는 수열은 무엇일까?
- 세번째에 있는 숫자 1을 꺼낸다.
- 다섯번째에 있는 숫자 3을 꺼낸다.
- 여섯번째에 있는 숫자 5를 꺼낸다.
이렇게 만들어진 수열 [1, 3, 5]가 위 수열에서 만들 수 있는 최장 증가 부분 수열에 해당하고 길이는 3이 된다.
이렇게 어떤 수열에서 최장 증가 부분 수열의 길이를 구할 수 있는 방법에는 크게 2가지가 있다.
- Dynamic Programming (동적 계획법)
- Binary Search (이분 탐색)
두 방법은 시간 복잡도에서 차이가 있다. 각각의 방법에 대해서 알아보자.
1. Dynamic Programming을 사용한 LIS 구하기
dp를 이용한 방법은 O(N^2)의 시간이 걸린다. 이 방법은 입력 받은 배열의 숫자를 하나씩 살펴보며 이를 통해 LIS의 길이를 구하는 방법이다. 위의 예제의 수열을 사용하여 이 과정을 살펴 보자.

먼저 dp[0]은 위와 같이 1로 초기화 해준다. 증가 부분 수열의 길이는 1부터 시작한다.
다음으로 array[1]을 살펴보자. 앞의 array의 값과 비교했을 때 작으므로 dp[1]에는 1이 들어간다.
array[2] 역시 앞의 array 값들과 비교했을 때 작으므로 dp[2]에는 1이 들어간다.
array[3]은 array[1]과 array[2]에 비해 큰 값이다. dp[1]과 dp[2]는 값이 1로 같으므로 dp[3]에는 1 + 1인 2가 들어가게 된다.
array[4]는 array[1]과 array[2]에 비해 큰 값이다. dp[1]과 dp[2]는 값이 1로 같으므로 dp[3]에는 1 + 1인 2가 들어가게 된다.
마지막 array[5]는 array[1], array[2], array[3], array[4]에 비해 큰 값이다. 이 중 dp[3]과 dp[4]가 2로 가장 큰 값이므로 dp[5]에는 2 + 1인 3이 들어가게 된다.
이렇게 만들 수 있는 모든 부분 증가 수열의 길이를 구하였고 이중 LIS의 길이는 dp배열에서 가장 큰 값에 해당하는 3에 해당된다. 파이썬으로 해당 알고리즘을 구현하면 다음과 같다.
array = [5, 2, 1, 4, 3, 5]
dp = [1 for _ in range(len(array))]
for i in range(1, len(array)):
for j in range(i): # array의 처음부터 i-1번째 인덱스까지
if array[i] > array[j]: # 숫자의 크기를 비교하여 현재 값이 더 크면
dp[i] = max(dp[i], dp[j] + 1) # dp 배열의 값을 더 큰 값으로 갱신
2. Binary Search를 사용한 LIS 구하기
dp를 사용한 LIS를 구하기 위해서는 수열의 값을 하나씩 비교해가며 길이를 구하기 때문에 O(N^2)의 시간이 걸리게 된다. 하지만 이분탐색을 사용하면 모든 수열의 값을 일일히 비교하지 않고 LIS의 길이를 구할 수 있기 때문에 O(N log N)의 시간으로 해결할 수 있다.
이를 위해 배열은 dp와 x 총 2가지가 사용된다. dp는 위와 같이 증가 부분 수열의 길이를 저장해 놓는 배열이고 x는 해당 부분 수열의 값들을 저장해 놓는 배열로 증가 부분 수열의 길이가 n일 때,
위의 예제를 이분 탐색을 사용하여 LIS의 길이를 구해보자. 처음에는 dp[0]에 1을 넣어주고 x[0]에는 array의 첫 번째 값인 5를 넣어준다.
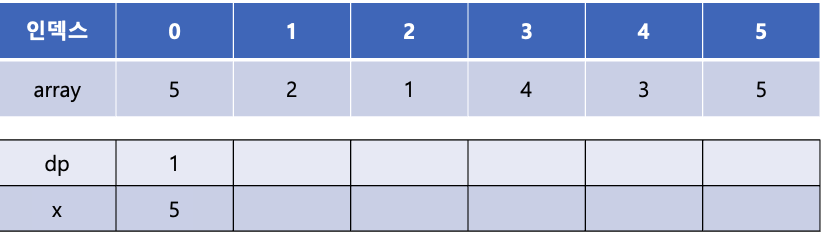
이제 array[1]의 값이 x 배열에서 어디에 들어갈 수 있는지를 이분탐색을 통해 찾는다. 2는 x 배열의 0번째 인덱스에 들어갈 수 있으며 x[0]에 있는 5보다 작다. 이렇게 해당 인덱스에 있는 x 배열의 값보다 현재 값이 작을 경우에는 x 배열의 값을 갱신해 준다. 즉, 위에서는 x[0]에 5대신 2가 들어가게 된다.
이는 길이가 1인 증가 부분 수열이 {5}와 {2}가 있는데 이 수열 중에서 끝 값이 더 작은 2를 x 배열에 저장해 놓는다는 의미이다.
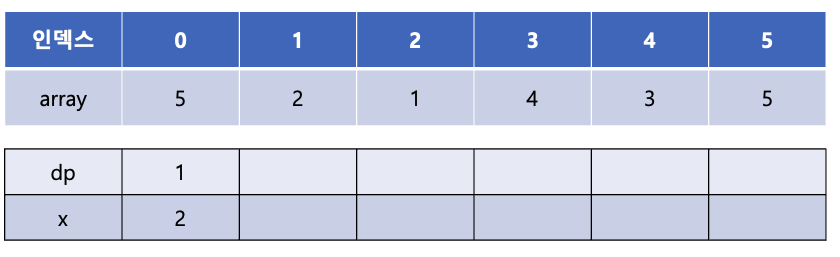
이제 array[2]의 값인 1을 살펴 보면 역시 x의 0번째에 들어갈 수 있고 이는 현재 x[0]의 값인 2보다 작기 때문에 x[0]을 1로 갱신해준다.
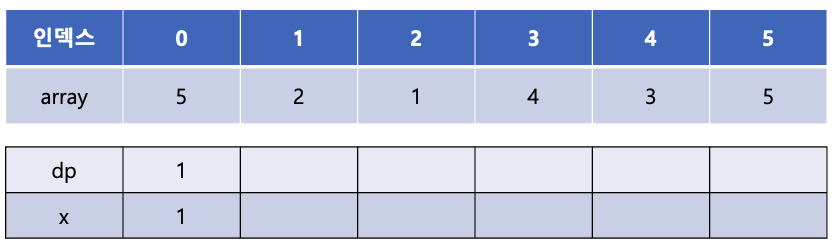
array[3]의 값인 4는 x 배열의 마지막 값인 1보다 크므로 새롭게 x 배열에 추가해 줄 수 있다. x[1]에 4를 추가해 주고 dp[1]에는 dp[0] + 1인 값 1을 넣어준다.
이는 증가 부분 수열의 길이가 2인 수열 중 끝이 4로 끝나는 수열이 있다는 것을 의미한다.
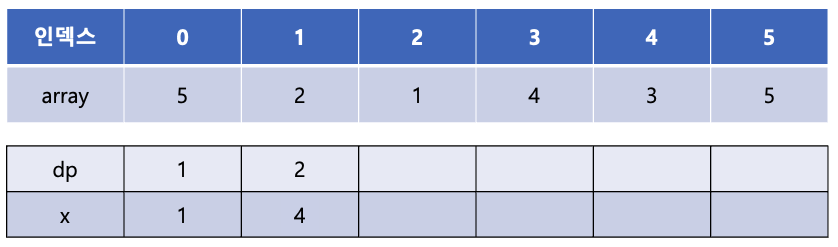
array[4]의 값인 3은 x 배열에서 1번째 인덱스에 들어갈 수 있으며 현재 x[1]의 값인 4보다 작다. x[1]의 값을 3으로 갱신해 준다.
이는 증가 부분 수열의 길이가 2인 수열 중 끝이 4와 3인 수열 중 더 작은 값인 3을 x 배열에 저장해 놓는다는 의미이다.
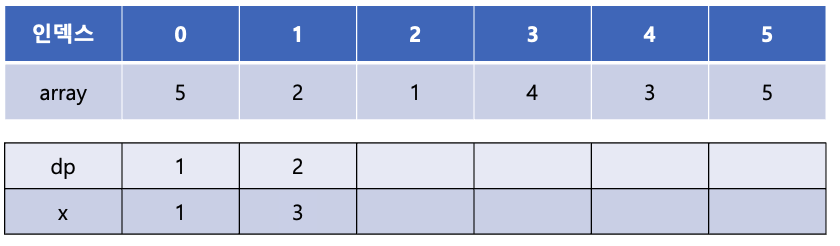
마지막으로 array[5]의 값인 5를 x 배열의 몇 번째에 넣을 수 있는지를 이분탐색을 통해 찾는다. x 배열의 마지막 값인 3보다 크므로 x 배열에 새롭게 5를 추가해 주고 dp 배열에는 dp 배열의 마지막 값에 + 1을 해주어 3을 추가해준다.
이는 증가 부분 수열의 길이가 3인 수열 중 끝이 5인 수열이 있다는 것을 의미한다.
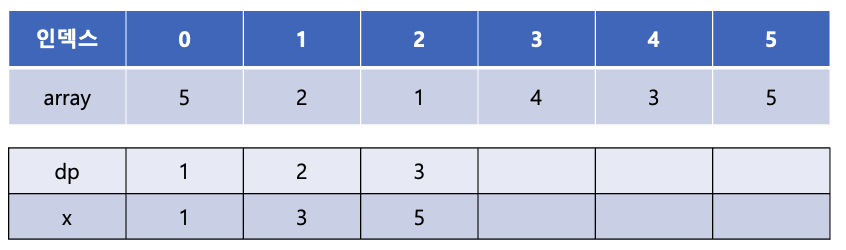
이렇게 array의 마지막 까지 탐색을 끝내고 나면 위와 같이 dp 배열과 x 배열이 완성되고 이를 통해 LIS의 길이는 3이라는 것을 알 수 있다.
x 배열은 항상 오름차순으로 정렬 되어 있기 때문에 array의 값이 x 배열의 어느 위치에 들어갈 수 있는지를 이분 탐색을 활용하여 찾을 수 있다. 파이썬에서는 bisect를 사용하여 이를 쉽게 구현할 수 있다.
from bisect import bisect_left
array = [5, 2, 1, 4, 3, 5]
dp = [1]
x = [array[0]]
for i in range(1, len(array)):
if array[i] > x[-1]: # 현재 값이 x 배열의 마지막 값보다 클 경우
x.append(array[i]) # x 배열에 현재 값을 추가해 주고
dp.append(dp[-1] + 1) # 증가 부분 수열의 길이를 1 증가시킨다.
else: # 그렇지 않을 경우
idx = bisect_left(x, array[i]) # 현재 값이 x 배열의 몇 번째 인덱스에 들어갈 수 있는지를 찾아서
x[idx] = array[i] # x 배열의 idx 위치에 현재 값을 넣어준다.
참고
'Algorithm > Basic' 카테고리의 다른 글
| [Algorithm] 세그먼트 트리 (Segment Tree) (1) | 2022.04.22 |
|---|---|
| [Algorithm] 위상 정렬 (Topology Sort) (0) | 2022.04.11 |
| [최단경로 알고리즘 - 3] 벨만 포드 알고리즘 (0) | 2021.11.14 |
| [최단경로 알고리즘 - 2] 플로이드 워셜 알고리즘 (1) | 2021.11.11 |
| [최단 경로 알고리즘 - 1] 다익스트라 알고리즘 (0) | 2021.10.31 |




댓글